 |
12 | |||||
| �γ� | ��� | ���� | ���� |
2020���ͳ��ʵ��̳�֪ʶ�㾫��59
���Ľ� ��������ļ�����֯��ʽ
һ��ѡ�������֯��ʽ��ԭ��
���г�������ĺ���������������ָ��������ƶ�����ָ�ꡣ�ɼ��������ƶϵĻ���������������������г�ѡ����������������д����ԣ�Ӧ��������Ҫ���ĵ����⡣Ȼ������ᾭ�������Ǹ��ӵģ����в�ͬ���ص㡣��ȡ����ʱҪ�����䲻ͬ�ص㣬ѡ�ú��ʵij�����֯��ʽ�������ij�־�������ѡ�����ֳ�����֯��ʽ�����������������ص��⣬��Ӧ������������ԭ��
��һ����ȡ������λ�������ԭ�������˵������֯����ʱ��Ӧ��֤������ÿ����λ����ͬ�ȵĻ��ᱻ���С�
������ʵ�����ij���Ч��ԭ�������˵���Խ��ٵĵ�����û�ýϺõij���Ч��������֯��������ʱ�����Dz���Ƭ���ǿ�����������С�ķ�������õķ�������Ϊ���������С����������ҲӦҪ��Ӧ��Щ��ʵ���ϣ��������������������һ����Χ�ģ����ǵ���������һ����������Χ�ڣ�Ҫѡ����龭�����ٵķ�����
���ڽ��ܼ��ֳ��õij�����֯��ʽ����ʵ�ʳ�����������Բ�ͬ������ο�ѡ�á�2020���ͳ��ʦ����ʱ���ͳ��ʦ���Խ̲�ͳ��ʱ���ȵ�ͳ��ʦ������ͳ��ʦ�����湺����ͼƬ ��
��
�������������
������������ֳƴ�����������ǰ������ԭ��ֱ�Ӵ������г�ȡһ���ֵ�λ��Ϊ�����������������һ����֯��ʽ��������֯��ʽ��Ӧ�ھ������壬������ij�ֵ����־�ĵ�λ���ȵطֲ�������ĸ������֡��ڽ��г���֮ǰ��Ӧ������ȷ������������ǿ���ѡ����Ϊ���������嵥λ��������Ȼ��Գ������е�ÿ����λ���б�ţ����������ѡ����Ҫ�ĵ�λ����
ǰ�漸�������۵��йظ���ͼ��㹫ʽ������Լ�����������Եģ���ǰ����ܵij������ͱ�Ҫ������Ŀ�ļ��㷽�����Լ������������Ӧ�ġ�
�������ͳ���
���ͳ����ֳƷ��������ֲ���������Ƚ������е����е�λ���յ����־��������йصı�־�ֳ������࣬Ȼ���ڸ���������س�ȡ������λ�����ֳ����ķ������ǽ����鷨�ͼ�����������ϵķ���������Ҫ���öԵ���������˽��֪ʶ�����ڸ����г�ѡ������λ��Ҫ�������ԭ��������ĺô����dz�ȡ����������������Ըߣ���������С��
���ͳ����ַ����ȱ��������Ͳ��ȱ����������ȱ��������ǰ��������嵥λ��ռȫ�����嵥λ���ı����ڸ����з���������λ���ģ�ʹ����������λ��������������֮�ȵ��ڸ������嵥λ����ȫ�����嵥λ��֮�ȡ�û�����干�ֳ�K���飨�ࣩ��N��i(i=1��2������k)�ǵ�i������嵥λ����n��i�ǵ�i������������λ����������������
![]()
ȫ�����嵥λ��
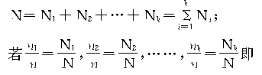
![]() ����Ϊ�ȱ�������������Ϊ���ȱ���������
����Ϊ�ȱ�������������Ϊ���ȱ���������
�����ͳ���ʱ�����ü�ƽ���ķ��������i(i=1��2������k)�������ƽ����![]() ����
����
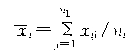 ʽ��
ʽ��![]() ����ʾ��i��������λ�ı�־ֵ���ü�Ȩƽ���ķ�������ȫ��������ƽ����
����ʾ��i��������λ�ı�־ֵ���ü�Ȩƽ���ķ�������ȫ��������ƽ����![]() ��Ȩ���Ǹ�������嵥λ�����ڵȱ�������ʱ��Ȩ��Ҳ������������λ������
��Ȩ���Ǹ�������嵥λ�����ڵȱ�������ʱ��Ȩ��Ҳ������������λ������
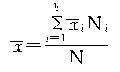
�ڵȱ�������ʱ��Ҳ���ԣ�
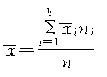
�����ͳ���ʱ����������Ĺ�ʽ�������ƽ����
1.����ƽ�����ij���ƽ�����̪�x��
��![]() ������i���ࣨ�飩�����ڷ�����ظ�����ʱ��
������i���ࣨ�飩�����ڷ�����ظ�����ʱ��
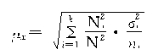
��ʵ�ʼ���ʱ����������ڷ���![]() δ֪�����ø������������
δ֪�����ø������������![]()
![]() ���档
���档
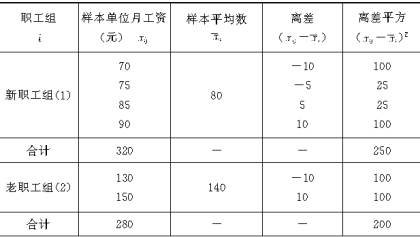
�־���˵�����ͳ��������³���ƽ�����ļ��㷽������ij��ҵ��120�����ˣ���������ְ��80������ְ��40�����ְ����嵥λ��5�����÷��������ʽ���������й���ȡ6�� ���˵������ǵ��¹���ˮƽ�������������±���
��7-5��
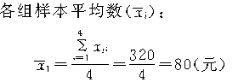
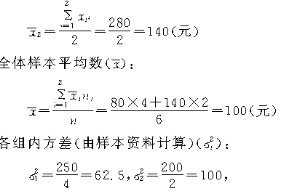 ��
��
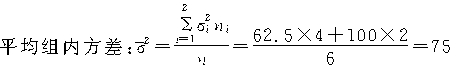
������������λ�����ظ�����������ȡ�ģ������ƽ�����Ϊ��
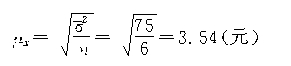
�����ճ̶�Ϊ95��������Ӧ�ĸ��ʶ�Ϊt=1.96�������������Ϊ��
![]()
����ƽ�����ʵ�����Ϊ��
![]() ������120�����˵�ƽ��������93.06Ԫ��106.94Ԫ֮�䡣
������120�����˵�ƽ��������93.06Ԫ��106.94Ԫ֮�䡣
�ڲ��ظ����������£����ͳ����ij���ƽ�����Ϊ��
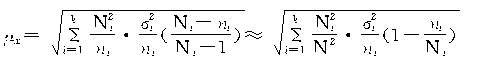
���ڵȱ������������£�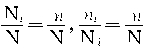 �����У�
������
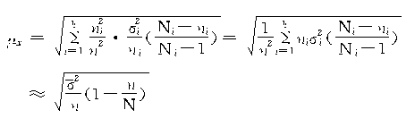
���У�![]() ������ϵ������Ϊ�����Ǵӷֺõĸ������н��в��ظ������������Ƿֱ�Ը�������ڷ������������
������ϵ������Ϊ�����Ǵӷֺõĸ������н��в��ظ������������Ƿֱ�Ը�������ڷ������������
������������Ͻ��м��㡣������������λ�ǰ����ظ�����������ȡ�ģ������ƽ�����Ϊ��
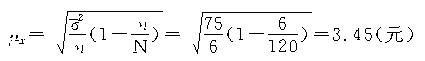
�����ճ̶���Ϊ95����ȫ�幤�˵�ƽ�����ʵ�����Ϊ��
![]() ��93.24Ԫ��106.76Ԫ֮�䡣
��93.24Ԫ��106.76Ԫ֮�䡣
2.���������ij���ƽ�����̪�p����
�����ij���ƽ�������ƽ�����ij���ƽ����������һ���ģ�ֻ�а�P(1-P��i)��Ϊ��i�����ڳ����ķ������![]() ���ɣ�����
���ɣ�����
���ظ����������£�

ʽ�У���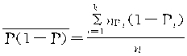 ���dz�����ƽ�����ڷ���ڲ��ظ����������£�
���dz�����ƽ�����ڷ���ڲ��ظ����������£�
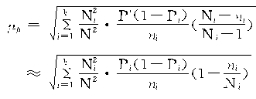
�ڵȱ�������ʱ��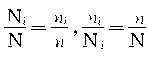 �����У�
������
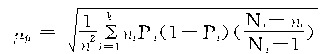
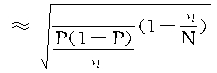
�ġ��Ⱦ����
�Ⱦ�����ֳƻ�е���������Ƚ��������λ��һ��˳���Ŷӣ��������嵥λ����������λ��������������![]() ��Ȼ������������ѡ������λ���ڰ����嵥λ�����Ŷ�ʱ�����ر�־�ŶӺ��йر�־�Ŷ����ַ�������ν�ر�־�ŶӾ��ǰ����嵥λ����������־�صı�־�Ŷӣ������ѧ���ɼ������ϱʻ��Ŷӡ���ν�йر�־�Ŷӣ��ǰ������ı�־�й�ϵ�ı�־�Ŷӣ�����鹤�˵Ĺ������밴�����Ŷӡ�
��Ȼ������������ѡ������λ���ڰ����嵥λ�����Ŷ�ʱ�����ر�־�ŶӺ��йر�־�Ŷ����ַ�������ν�ر�־�ŶӾ��ǰ����嵥λ����������־�صı�־�Ŷӣ������ѧ���ɼ������ϱʻ��Ŷӡ���ν�йر�־�Ŷӣ��ǰ������ı�־�й�ϵ�ı�־�Ŷӣ�����鹤�˵Ĺ������밴�����Ŷӡ�
��ȫ�������й���N����λ������г�ȡ������λ��Ϊ��������N����λ�ŶӺ��ٰ�N����λ�ֳɼ�����ȵ�С�飬ÿһ���ж��� ����λ���Ⱦ�������õ������ַ�����������Ⱦ������������Ⱦ������������ԳƵȾ������
����λ���Ⱦ�������õ������ַ�����������Ⱦ������������Ⱦ������������ԳƵȾ������
1.������Ⱦ���������ڵ�һС���f����λ�������ѡһ����λ��Ȼ��ÿ��f����λ��ȡһ����λ��ֱ���鹻n����λ�����ֳ���������Ա����ڳ�ȡ��һ��������λ������һ��������λ��λ��ȷ���Ժ������������λ��λ��Ҳѵȷ���ˡ������йر�־�Ŷӣ������鵽��������λ���־ֵ���ܳ���ϵͳ��ƫ��ƫ�͵������
2.������Ⱦ���������ѵ�һС����е㵥λ��Ϊ��һ�����ѡ��λ��Ȼ��ÿ��f����λ��ѡ����λ��ֱ���鹻n����λ��������йر�־�Ŷӣ����ֳ���������Ȼ��ij�ֳ����ϱ�������������������Ⱦ���������IJ��㣬�������ƻ����ԭ��Ŀ����ԡ�
3.������ԳƵȾ���������ӵ�һ��С����������һ����λ��Ϊ��һ��������λ��Ȼ��ÿ����С��ϲ���һ�����飬��ÿ�������жԳƳ������������λ��ʹÿ��������λ����������������ľ�����ȡ���������λ��nΪ����ʱ�������ϲ��ɴ����ʣ��һ��С�顣��Ӧ��������������λ�ã�������������ȷ��һ����λ��Ϊ��һ����λ��λ��Ȼ���ڸ������߲��ɴ��飬���öԳƳ����İ취���������λ��������ԳƵȾ����������������ǰ���ַ������ŵ㣬���������ǵľ����ԡ�
�Ⱦ�����ij���ƽ��������������ǵģ��ر�־�ŶӵȾ�����������ڼ������������Ϊ���ر�־�Ŷ�ʱ���õı�־�������Ŀ�أ�����Ϊ�����嵥λ�����κ�ѡ�����С����ԣ�ÿ����λ�����κ�λ�ö�������ģ����ÿ����λ��������Ϊ������λҲ������ġ���ˣ��������ƽ�����ʱ��һ����Ϊ�����ռ���������ķ���ȥ������
������6����һ�����س�250�ף���70�ף�������150�����ס��ֶ����ص����ײ��õȾ������ʽ����ȡ30��3�׳���Ϊ������ʵ��ʵ�⣬�������ص����ײ������乤������ͼ���������£�
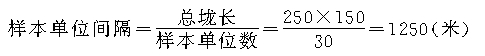
���׳����������Ȼ�γɵģ�����Ϊ���ر�־�Ŷӣ�����ð�����Ⱦ��������������������Ⱦ������ɣ�����һ������������е�ѡ��ѡȡ��һ��������λ�����ӵ�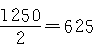 �״���ʵ���ڵرߵ�������е㣩��ǰ���ȡ1.5��Ϊ��һ��������λ���Ժ���ÿ��1250��ǰ���1.5��ȡһ��������λ��һֱȡ��30��������λΪֹ��ʵ��ʵ���ø�������λ�IJ�����
�״���ʵ���ڵرߵ�������е㣩��ǰ���ȡ1.5��Ϊ��һ��������λ���Ժ���ÿ��1250��ǰ���1.5��ȡһ��������λ��һֱȡ��30��������λΪֹ��ʵ��ʵ���ø�������λ�IJ�����
����������ʾ��
���7-6��������ʵ����������
��7-6��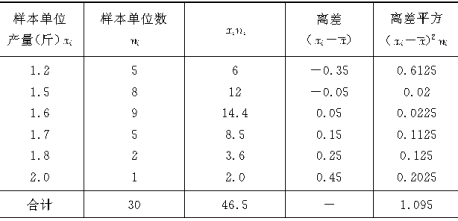
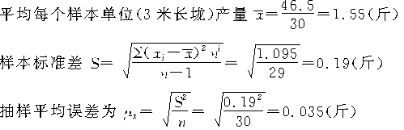
��95���ĸ��ʱ�֤�£�ÿ3�׳����ƽ�������Ŀ��������ǣ�
1.55��1.96��0.035������1.48����1.62��֮�䡣��
ÿĶ��ƽ������[ZK(]��������λƽ��������ÿĶ��������λ��

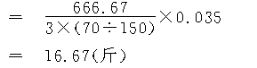
��ƽ��Ķ�����Ŀ��ܷ�Χ�ǣ�
738.1��1.96��16.67������705.43����770.77��֮�䡣��
�������ص�����ǣ�
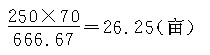
���������ص��ܲ��������䷶Χ�ǣ�
1817.54����20232.71��֮�䣬����Ϊ95����
�йر�־�ŶӵȾ�������Կ�����һ����������ͳ�����ֻ�����Ƿ����ϸ������ÿһ����ֻ��һ��������λ�����ԣ������ƽ�����ļ��㷽��һ����Ϊ���������ͳ��������µļ��㹫ʽ���㡣��
ƽ�����ij���ƽ�������ͳ���ʱΪ��
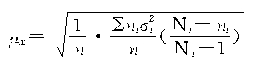
ע��Ⱦ����ʱ��ÿ��ֻ��һ����λ����n��i=1����
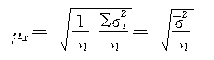
ʽ�У�![]() ��Ϊƽ�����ڷ���Ǹ����ڷ���ļ�����ƽ���������ҿ��Կ������Ⱦ������Ȼ�����ظ�����������ʵ���Ϻ��ظ�����һ�������������ظ������벻�ظ������������㹫ʽ��ͬ���������ij���ƽ�������㹫ʽΪ��
��Ϊƽ�����ڷ���Ǹ����ڷ���ļ�����ƽ���������ҿ��Կ������Ⱦ������Ȼ�����ظ�����������ʵ���Ϻ��ظ�����һ�������������ظ������벻�ظ������������㹫ʽ��ͬ���������ij���ƽ�������㹫ʽΪ��
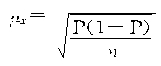
��ʵ�ʼ���ʱ�������и��Ⱦ��������ڷ���һ����δ֪�ģ���Ҳ�����������ϴ��棬��Ϊһ������ֻ��ȡһ��������λ����ʱ�����ǿ������йر�־�ĸ����Ⱦ��������ڷ��������Ƶش��档
�塢��Ⱥ����
��Ⱥ�������Ƚ������Ϊ����Ⱥ��Ȼ������س�ѡһЩȺ���Գ鵽������Ⱥ�е����е�λ����ȫ����顣����һȺ������һ����λ������Ⱥ�����Ϳ�����Ϊ���������嵥λ�ļ�����������������Ϊ����Ⱥ��ÿһȺ�а����ĵ�λ��������ȣ�Ҳ���Բ���ȡ�
����������Ⱥ�����ij���ƽ�����������ֳ�RȺ������ش��г�ȡrȺ���������Ϊ�˼����㣬���Ǽ����Ⱥ�а����ĵ�λ������ȣ��趼������M����λ���ɴ˲������Ƹ�Ⱥ�а����ĵ�λ������ȵ������
���i(i=1��2����R)Ⱥ�е�j(j=1��2����m)����λ�ı�־ֵΪxij�������iȺ�ı�־ֵx��i���������λ�ı�־ֵ��ƽ������ʾ����
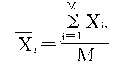
����������Ⱥ��ƽ����![]() Ϊ��
��
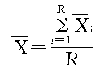
ƽ������Ⱥ�䷽��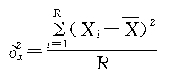
���ռ�������������Σ���Ⱥ������ƽ�����ij���ƽ�����![]() Ϊ��
��
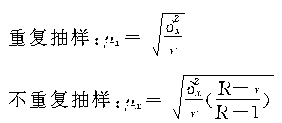
�ڼ���ʱ��������Ⱥ�䷽��δ֪��Ҳ����������Ⱥ�䷽����档
�֣����iȺ�ij���Ϊ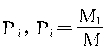 ���������Ϊ
���������Ϊ![]() ����Ϊ�����Ⱥ�е����嵥λ����ȣ�ΪM�����ԣ�
����Ϊ�����Ⱥ�е����嵥λ����ȣ�ΪM�����ԣ�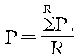 ���������Ⱥ�䷽��Ϊ��
���������Ⱥ�䷽��Ϊ��
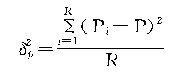
�����ij���ƽ�����![]() Ϊ��
��
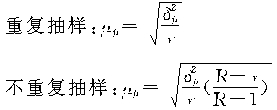
������7��ij��ͳ�ƾִ�ȫ��1000������������100���壬��������ļ�������ֻ�����������������ϣ�������������ÿ���������Ļ�������ȣ�����95.45���ĸ��ʹ���ȫ��ƽ��ÿ���������ݵ�ֻ�������䷶Χ����
��Ⱥ������������
��7-7��
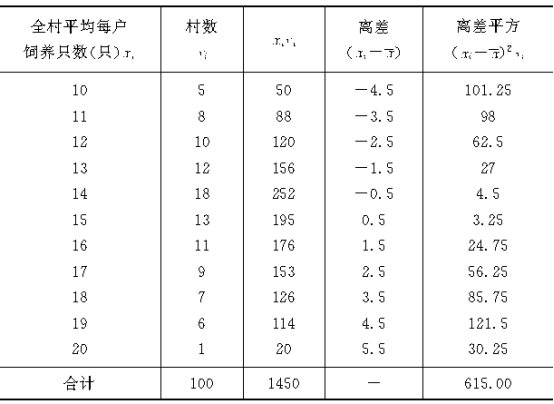
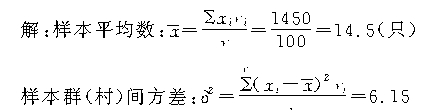
����������ʾ��

��������
��γ������Ȱ����廮��Ϊ����Ⱥ���ٰ�ÿȺ�ֱ��ֶ�����Ϊ���ɴ�Ⱥ���ٰ�ÿ����Ⱥ������Ϊ��С��Ⱥ���������ƣ�ֱ�����嵥λ������ʱ����һ��������������س�ȡ����Ⱥ���ڶ�������ѡȺ�зֱ�����س�ȡ���ɴ�Ⱥ���������ƣ�ֱ����ȡ������λ�����磬ijʡͳ�ƾ�Ҫ�����ʡũ����������������ȫʡ100����������س�20���أ�������ѡ��ÿ�����ж�����3���磬������ѡ�ĸ����ж������10��ũ��������һ������Ϊn=10��3��20��600�����������������γ����������Ǵ�Ⱥ����Ⱥ���С��Ⱥ��ÿȺ�Ĵ�С������ȣ�Ҳ���Բ���ȣ�ÿ�δ���ѡȺ�г�ȡ��һ�ε�Ⱥ������λ����������ȣ�Ҳ���Բ���ȡ��������������γ���Ϊ�����������ص㼰�йؼ��㷽����
�����γ������ԣ��Ƚ����廮��ΪR��Ⱥ����ÿȺ�а���M��i(i=1��2����R)����λ�������嵥λ��N=M��1+M��2+����+M��R������ʱ����һ�δ�R��Ⱥ������س�ȡr��Ⱥ���ڶ��δ���ѡ��r��Ⱥ�зֱ�������س�m��i(i=1��2����r)����λ������һ������Ϊn=m��1+m��2+����m��r�����������γ��������ͳ�������Ⱥ�����Ľ�ϣ���������֯��ʽ�������Ȱ�����ֳ�����Ⱥ���ࡢ�飩����֮ͬ�����±���ʾ������7-8����
���ֳ�����֯��ʽ�ıȽ�
��7-8��
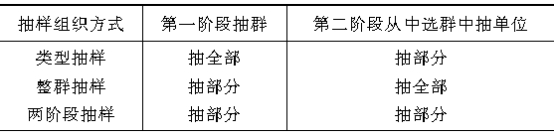 Ϊ�˼��㣬��ÿȺ�а����ĵ�λ������ȣ�ΪM�����Ӹ���ѡȺ�г���ĵ�λ��Ҳ����ȣ�Ϊm�������γ������ȴ�����R��Ⱥ������س�ȡr��Ⱥ���ִ�r��Ⱥ�ж��ֱ�����س�ȡm����λ�����һ������n=rm��������
Ϊ�˼��㣬��ÿȺ�а����ĵ�λ������ȣ�ΪM�����Ӹ���ѡȺ�г���ĵ�λ��Ҳ����ȣ�Ϊm�������γ������ȴ�����R��Ⱥ������س�ȡr��Ⱥ���ִ�r��Ⱥ�ж��ֱ�����س�ȡm����λ�����һ������n=rm��������
��xij����ʾ��i��i=1��2����r��������Ⱥ�е�j��j=1��2����m������һ��λ�ı�־ֵ�����i������Ⱥ������ƽ����![]() Ϊ��
��
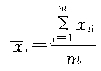
ȫ������ƽ����![]() ������ʽ���㣺
������ʽ���㣺
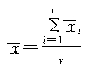 ���γ����ij���ƽ���������ƽ������ƽ������������ɣ�һ����ƽ��Ⱥ�ڷ����
���γ����ij���ƽ���������ƽ������ƽ������������ɣ�һ����ƽ��Ⱥ�ڷ����![]() ���裺
���裺

ΪȺ�䷽������γ�����ƽ�����ij���ƽ������xΪ��
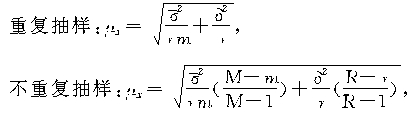
��ʵ�ʼ���ʱ��������ָ�꣨��Ⱥ�ڷ���![]() ��Ⱥ�䷽��
��Ⱥ�䷽��![]() �����õ�ʱ��������Ӧ������ָ����档
�����õ�ʱ��������Ӧ������ָ����档
������8��ij��ͳ�ƾ���ȫ��15�����������ȡ3���磬��ÿ�����1500ũ��������ÿ����ѡ���������ȡ5��ũ������ȫ����������ĵ��飬���������������±�������6-9��
��7-9 ��������������� ��
����95���ĸ��ʹ���ȫ��ũ�����˾���������䡣
����������ʾ��
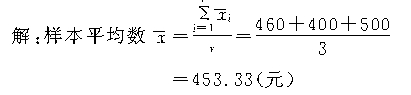
��Ⱥ�ڷ�����������ϼ��㣩��
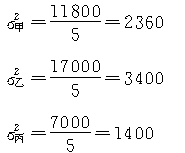
��ƽ�����ڷ��
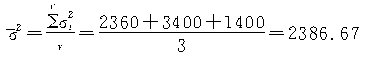
�֣�Ⱥ�䷽����������ϼ��㣩��
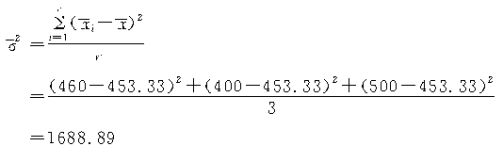 ����ƽ�����̪�x�������ظ�����ʱΪ��
����ƽ�����̪�x�������ظ�����ʱΪ��
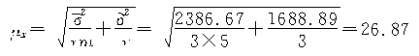
�ڲ��ظ�����ʱΪ��
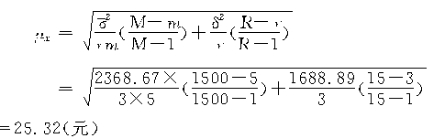
����F(t)=95%ʱ�����ʶ�t=1.96��ȫ��ũ�����˾���������䣬�ظ�����ʱΪ��

������9����2010�꣩���ݵڶ��ξ����ղ�����ij����������ҵ���廧10����ҵ��Ա��30���ˡ�����Ըõ�������ҵ���廧�ľ�Ӫ�����չ�������顣Ϊ�Ƚϲ�ͬ���������������ԣ��ֱ���ü�����������Դ�ҵ��Ա��Ϊ�ֲ��־�ķֲ�������������ղ�С��ΪȺ��λ����Ⱥ����������ȡ500�����廧��500�����廧��60���ղ�С�����ں�500�����廧�����е��飬���������±���
|
�������� |
�õ�������ҵ���廧���۶� | |
|
�����ֵ����Ԫ�� |
�������ֵ����Ԫ2�� | |
|
��������� |
535 |
2982 |
|
�ֲ�������� |
542 |
765 |
|
��Ⱥ���� |
524 |
6535 |
Ҫ��
1���ֱ�������95%���ʱ�֤�̶������ֳ�������������ҵ���廧���۶�������������������ֳ��������µĹ�����������ߣ�������1λС����
2�����ЧӦ��Deff���ĸ�����ʲô�������ֲ������������Ⱥ���������ЧӦ��������3λС����
3����ʵ�ʳ��������������ֳ��������������Խ��м�Ҫ���ۡ�
����������ʾ����������=Z*S ���ʱ�֤�ȳ��Ա���
����� E=��/Y
1������������źֱ�Ϊ��54.6�� 27.7�� 80.8
�����������E=1.96*54.6/535=0.2
�ֲ����������E=1.96*27.7/542=0.3
��Ⱥ���� ��E=1.96*80.8/524=0.1
2�����ЧӦ������Ϊ���������ʽ�µij���������Լ����������ʽ�³���������̡���ͬ������ʽ�µ����ЧӦ�ֱ�Ϊ��
�����������deff=1 �ֲ����������deff<=1
��Ⱥ���������deff>= 1��е���������deff��1
�ֲ����=765/2982=0.257
��Ⱥ����=6535/2982=2.191
�����������ϵͳ�������ֲ�����Ĺ�ͬ�ص����ڳ���������ÿһ�����屻��ȡ�ĸ�����ȣ���������Щ���������Ŀ��Ժ�ƽ�ԣ����м�������������������ij����������ڽ���ϵͳ�����ͷֲ����ʱ��Ҫ�õ�����������������������еĸ���������ʱ�������ü�����������������еĸ������϶�ʱ��������ϵͳ����������֪�����ɲ������Եļ��������ʱ������һ������ǡ�����о��������������ʱ�������÷ֲ����.
������10����ij��ʵʩһ��������飬�����������飬Ԥ�ƿջ���Ϊ5%����ܷõ�ԭ����ɵ��ش���Ϊ15%����Ҫ��֤������Ч�������ܹ��ﵽ200��������Ӧ��ȡ������������
����������ʾ����Ҫ��ȡX������5%�Ŀջ��ʣ����ܳ��ϵ�ֻ�У�1-5%�����ش���Ϊ15%��˵���ܻش��ֻ��1-15%
X��1-5%����1-15%��=200 X=247.2 ȡ��=248
������11����2012�꣩��֪ij��ҵְ��������������£�
|
��ͬ���� ������ |
ְ������ ��Ni�� |
�������� (ni) |
��ƽ�����루Ԫ�� (x) |
������Ԫ�� ��Si�� |
|
������ |
200 |
10 |
13200 |
480 |
|
һ������ |
1600 |
80 |
8040 |
300 |
|
������ |
1200 |
60 |
6000 |
450 |
|
�ϼ� |
3000 |
150 |
- |
- |
�����ϱ����ϼ��㣺1��������ƽ�����룻2����ƽ������ij�����3������Ϊ95%ʱ��ְ����ƽ������Ŀ��ܷ�Χ��
����������ʾ��
1��������ƽ�������
![]()
ְ����ƽ������=![]() ��Ԫ��
��Ԫ��
2����ƽ������ij�����
![]()
�������![]()
����Ϊ95%ʱ��ְ����ƽ������Ŀ��ܷ�Χ:
�����������=0.6827��29.60=20.21��Ԫ����
����ֵ=630.67-20.21=610.46��Ԫ��
����ֵ=630.67+20.21=650.88��Ԫ��
ְ����ƽ������Ŀ��ܷ�Χ: ��610.46Ԫ--650.88Ԫ����
2020���ͳ��ʵ��̳�֪ʶ�㾫��59
���Ľ� ��������ļ�����֯��ʽ
һ��ѡ�������֯��ʽ��ԭ��
���г�������ĺ���������������ָ��������ƶ�����ָ�ꡣ�ɼ��������ƶϵĻ���������������������г�ѡ����������������д����ԣ�Ӧ��������Ҫ���ĵ����⡣Ȼ������ᾭ�������Ǹ��ӵģ����в�ͬ���ص㡣��ȡ����ʱҪ�����䲻ͬ�ص㣬ѡ�ú��ʵij�����֯��ʽ�������ij�־�������ѡ�����ֳ�����֯��ʽ�����������������ص��⣬��Ӧ������������ԭ��
��һ����ȡ������λ�������ԭ�������˵������֯����ʱ��Ӧ��֤������ÿ����λ����ͬ�ȵĻ��ᱻ���С�
������ʵ�����ij���Ч��ԭ�������˵���Խ��ٵĵ�����û�ýϺõij���Ч��������֯��������ʱ�����Dz���Ƭ���ǿ�����������С�ķ�������õķ�������Ϊ���������С����������ҲӦҪ��Ӧ��Щ��ʵ���ϣ��������������������һ����Χ�ģ����ǵ���������һ����������Χ�ڣ�Ҫѡ����龭�����ٵķ�����
���ڽ��ܼ��ֳ��õij�����֯��ʽ����ʵ�ʳ�����������Բ�ͬ������ο�ѡ�á�2020���ͳ��ʦ����ʱ���ͳ��ʦ���Խ̲�ͳ��ʱ���ȵ�ͳ��ʦ������ͳ��ʦ�����湺����ͼƬ��
�������������
������������ֳƴ�����������ǰ������ԭ��ֱ�Ӵ������г�ȡһ���ֵ�λ��Ϊ�����������������һ����֯��ʽ��������֯��ʽ��Ӧ�ھ������壬������ij�ֵ����־�ĵ�λ���ȵطֲ�������ĸ������֡��ڽ��г���֮ǰ��Ӧ������ȷ������������ǿ���ѡ����Ϊ���������嵥λ��������Ȼ��Գ������е�ÿ����λ���б�ţ����������ѡ����Ҫ�ĵ�λ����
ǰ�漸�������۵��йظ���ͼ��㹫ʽ������Լ�����������Եģ���ǰ����ܵij������ͱ�Ҫ������Ŀ�ļ��㷽�����Լ������������Ӧ�ġ�
�������ͳ���
���ͳ����ֳƷ��������ֲ���������Ƚ������е����е�λ���յ����־��������йصı�־�ֳ������࣬Ȼ���ڸ���������س�ȡ������λ�����ֳ����ķ������ǽ����鷨�ͼ�����������ϵķ���������Ҫ���öԵ���������˽��֪ʶ�����ڸ����г�ѡ������λ��Ҫ�������ԭ��������ĺô����dz�ȡ����������������Ըߣ���������С��
���ͳ����ַ����ȱ��������Ͳ��ȱ����������ȱ��������ǰ��������嵥λ��ռȫ�����嵥λ���ı����ڸ����з���������λ���ģ�ʹ����������λ��������������֮�ȵ��ڸ������嵥λ����ȫ�����嵥λ��֮�ȡ�û�����干�ֳ�K���飨�ࣩ��N��i(i=1��2������k)�ǵ�i������嵥λ����n��i�ǵ�i������������λ����������������
![]()
ȫ�����嵥λ��
![]() ����Ϊ�ȱ�������������Ϊ���ȱ���������
����Ϊ�ȱ�������������Ϊ���ȱ���������
�����ͳ���ʱ�����ü�ƽ���ķ��������i(i=1��2������k)�������ƽ����![]() ����
����
ʽ��![]() ����ʾ��i��������λ�ı�־ֵ���ü�Ȩƽ���ķ�������ȫ��������ƽ����
����ʾ��i��������λ�ı�־ֵ���ü�Ȩƽ���ķ�������ȫ��������ƽ����![]() ��Ȩ���Ǹ�������嵥λ�����ڵȱ�������ʱ��Ȩ��Ҳ������������λ������
��Ȩ���Ǹ�������嵥λ�����ڵȱ�������ʱ��Ȩ��Ҳ������������λ������
�ڵȱ�������ʱ��Ҳ���ԣ�
�����ͳ���ʱ����������Ĺ�ʽ�������ƽ����
1.����ƽ�����ij���ƽ�����̪�x��
��![]() ������i���ࣨ�飩�����ڷ�����ظ�����ʱ��
������i���ࣨ�飩�����ڷ�����ظ�����ʱ��
��ʵ�ʼ���ʱ����������ڷ���![]() δ֪�����ø������������
δ֪�����ø������������![]()
![]() ���档
���档
�־���˵�����ͳ��������³���ƽ�����ļ��㷽������ij��ҵ��120�����ˣ���������ְ��80������ְ��40�����ְ����嵥λ��5�����÷��������ʽ���������й���ȡ6�� ���˵������ǵ��¹���ˮƽ�������������±���
��7-5��
��
������������λ�����ظ�����������ȡ�ģ������ƽ�����Ϊ��
�����ճ̶�Ϊ95��������Ӧ�ĸ��ʶ�Ϊt=1.96�������������Ϊ��
![]()
����ƽ�����ʵ�����Ϊ��
![]() ������120�����˵�ƽ��������93.06Ԫ��106.94Ԫ֮�䡣
������120�����˵�ƽ��������93.06Ԫ��106.94Ԫ֮�䡣
�ڲ��ظ����������£����ͳ����ij���ƽ�����Ϊ��
���ڵȱ������������£������У�
���У�![]() ������ϵ������Ϊ�����Ǵӷֺõĸ������н��в��ظ������������Ƿֱ�Ը�������ڷ������������
������ϵ������Ϊ�����Ǵӷֺõĸ������н��в��ظ������������Ƿֱ�Ը�������ڷ������������
������������Ͻ��м��㡣������������λ�ǰ����ظ�����������ȡ�ģ������ƽ�����Ϊ��
�����ճ̶���Ϊ95����ȫ�幤�˵�ƽ�����ʵ�����Ϊ��
![]() ��93.24Ԫ��106.76Ԫ֮�䡣
��93.24Ԫ��106.76Ԫ֮�䡣
2.���������ij���ƽ�����̪�p����
�����ij���ƽ�������ƽ�����ij���ƽ����������һ���ģ�ֻ�а�P(1-P��i)��Ϊ��i�����ڳ����ķ������![]() ���ɣ�����
���ɣ�����
���ظ����������£�
ʽ�У������dz�����ƽ�����ڷ���ڲ��ظ����������£�
�ڵȱ�������ʱ�������У�
�ġ��Ⱦ����
�Ⱦ�����ֳƻ�е���������Ƚ��������λ��һ��˳���Ŷӣ��������嵥λ����������λ��������������![]() ��Ȼ������������ѡ������λ���ڰ����嵥λ�����Ŷ�ʱ�����ر�־�ŶӺ��йر�־�Ŷ����ַ�������ν�ر�־�ŶӾ��ǰ����嵥λ����������־�صı�־�Ŷӣ������ѧ���ɼ������ϱʻ��Ŷӡ���ν�йر�־�Ŷӣ��ǰ������ı�־�й�ϵ�ı�־�Ŷӣ�����鹤�˵Ĺ������밴�����Ŷӡ�
��Ȼ������������ѡ������λ���ڰ����嵥λ�����Ŷ�ʱ�����ر�־�ŶӺ��йر�־�Ŷ����ַ�������ν�ر�־�ŶӾ��ǰ����嵥λ����������־�صı�־�Ŷӣ������ѧ���ɼ������ϱʻ��Ŷӡ���ν�йر�־�Ŷӣ��ǰ������ı�־�й�ϵ�ı�־�Ŷӣ�����鹤�˵Ĺ������밴�����Ŷӡ�
��ȫ�������й���N����λ������г�ȡ������λ��Ϊ��������N����λ�ŶӺ��ٰ�N����λ�ֳɼ�����ȵ�С�飬ÿһ���ж�������λ���Ⱦ�������õ������ַ�����������Ⱦ������������Ⱦ������������ԳƵȾ������
1.������Ⱦ���������ڵ�һС���f����λ�������ѡһ����λ��Ȼ��ÿ��f����λ��ȡһ����λ��ֱ���鹻n����λ�����ֳ���������Ա����ڳ�ȡ��һ��������λ������һ��������λ��λ��ȷ���Ժ������������λ��λ��Ҳѵȷ���ˡ������йر�־�Ŷӣ������鵽��������λ���־ֵ���ܳ���ϵͳ��ƫ��ƫ�͵������
2.������Ⱦ���������ѵ�һС����е㵥λ��Ϊ��һ�����ѡ��λ��Ȼ��ÿ��f����λ��ѡ����λ��ֱ���鹻n����λ��������йر�־�Ŷӣ����ֳ���������Ȼ��ij�ֳ����ϱ�������������������Ⱦ���������IJ��㣬�������ƻ����ԭ��Ŀ����ԡ�
3.������ԳƵȾ���������ӵ�һ��С����������һ����λ��Ϊ��һ��������λ��Ȼ��ÿ����С��ϲ���һ�����飬��ÿ�������жԳƳ������������λ��ʹÿ��������λ����������������ľ�����ȡ���������λ��nΪ����ʱ�������ϲ��ɴ����ʣ��һ��С�顣��Ӧ��������������λ�ã�������������ȷ��һ����λ��Ϊ��һ����λ��λ��Ȼ���ڸ������߲��ɴ��飬���öԳƳ����İ취���������λ��������ԳƵȾ����������������ǰ���ַ������ŵ㣬���������ǵľ����ԡ�
�Ⱦ�����ij���ƽ��������������ǵģ��ر�־�ŶӵȾ�����������ڼ������������Ϊ���ر�־�Ŷ�ʱ���õı�־�������Ŀ�أ�����Ϊ�����嵥λ�����κ�ѡ�����С����ԣ�ÿ����λ�����κ�λ�ö�������ģ����ÿ����λ��������Ϊ������λҲ������ġ���ˣ��������ƽ�����ʱ��һ����Ϊ�����ռ���������ķ���ȥ������
������6����һ�����س�250�ף���70�ף�������150�����ס��ֶ����ص����ײ��õȾ������ʽ����ȡ30��3�׳���Ϊ������ʵ��ʵ�⣬�������ص����ײ������乤������ͼ���������£�
���׳����������Ȼ�γɵģ�����Ϊ���ر�־�Ŷӣ�����ð�����Ⱦ��������������������Ⱦ������ɣ�����һ������������е�ѡ��ѡȡ��һ��������λ�����ӵ��״���ʵ���ڵرߵ�������е㣩��ǰ���ȡ1.5��Ϊ��һ��������λ���Ժ���ÿ��1250��ǰ���1.5��ȡһ��������λ��һֱȡ��30��������λΪֹ��ʵ��ʵ���ø�������λ�IJ�����
����������ʾ��
���7-6��������ʵ����������
��7-6��
��95���ĸ��ʱ�֤�£�ÿ3�׳����ƽ�������Ŀ��������ǣ�
1.55��1.96��0.035������1.48����1.62��֮�䡣��
ÿĶ��ƽ������[ZK(]��������λƽ��������ÿĶ��������λ��
��ƽ��Ķ�����Ŀ��ܷ�Χ�ǣ�
738.1��1.96��16.67������705.43����770.77��֮�䡣��
�������ص�����ǣ�
���������ص��ܲ��������䷶Χ�ǣ�
1817.54����20232.71��֮�䣬����Ϊ95����
�йر�־�ŶӵȾ�������Կ�����һ����������ͳ�����ֻ�����Ƿ����ϸ������ÿһ����ֻ��һ��������λ�����ԣ������ƽ�����ļ��㷽��һ����Ϊ���������ͳ��������µļ��㹫ʽ���㡣��
ƽ�����ij���ƽ�������ͳ���ʱΪ��
ע��Ⱦ����ʱ��ÿ��ֻ��һ����λ����n��i=1����
ʽ�У�![]() ��Ϊƽ�����ڷ���Ǹ����ڷ���ļ�����ƽ���������ҿ��Կ������Ⱦ������Ȼ�����ظ�����������ʵ���Ϻ��ظ�����һ�������������ظ������벻�ظ������������㹫ʽ��ͬ���������ij���ƽ�������㹫ʽΪ��
��Ϊƽ�����ڷ���Ǹ����ڷ���ļ�����ƽ���������ҿ��Կ������Ⱦ������Ȼ�����ظ�����������ʵ���Ϻ��ظ�����һ�������������ظ������벻�ظ������������㹫ʽ��ͬ���������ij���ƽ�������㹫ʽΪ��
��ʵ�ʼ���ʱ�������и��Ⱦ��������ڷ���һ����δ֪�ģ���Ҳ�����������ϴ��棬��Ϊһ������ֻ��ȡһ��������λ����ʱ�����ǿ������йر�־�ĸ����Ⱦ��������ڷ��������Ƶش��档
�塢��Ⱥ����
��Ⱥ�������Ƚ������Ϊ����Ⱥ��Ȼ������س�ѡһЩȺ���Գ鵽������Ⱥ�е����е�λ����ȫ����顣����һȺ������һ����λ������Ⱥ�����Ϳ�����Ϊ���������嵥λ�ļ�����������������Ϊ����Ⱥ��ÿһȺ�а����ĵ�λ��������ȣ�Ҳ���Բ���ȡ�
����������Ⱥ�����ij���ƽ�����������ֳ�RȺ������ش��г�ȡrȺ���������Ϊ�˼����㣬���Ǽ����Ⱥ�а����ĵ�λ������ȣ��趼������M����λ���ɴ˲������Ƹ�Ⱥ�а����ĵ�λ������ȵ������
���i(i=1��2����R)Ⱥ�е�j(j=1��2����m)����λ�ı�־ֵΪxij�������iȺ�ı�־ֵx��i���������λ�ı�־ֵ��ƽ������ʾ����
����������Ⱥ��ƽ����![]() Ϊ��
��
ƽ������Ⱥ�䷽��
���ռ�������������Σ���Ⱥ������ƽ�����ij���ƽ�����![]() Ϊ��
��
�ڼ���ʱ��������Ⱥ�䷽��δ֪��Ҳ����������Ⱥ�䷽����档
�֣����iȺ�ij���Ϊ���������Ϊ![]() ����Ϊ�����Ⱥ�е����嵥λ����ȣ�ΪM�����ԣ����������Ⱥ�䷽��Ϊ��
����Ϊ�����Ⱥ�е����嵥λ����ȣ�ΪM�����ԣ����������Ⱥ�䷽��Ϊ��
�����ij���ƽ�����![]() Ϊ��
��
������7��ij��ͳ�ƾִ�ȫ��1000������������100���壬��������ļ�������ֻ�����������������ϣ�������������ÿ���������Ļ�������ȣ�����95.45���ĸ��ʹ���ȫ��ƽ��ÿ���������ݵ�ֻ�������䷶Χ����
��Ⱥ������������
��7-7��
����������ʾ��
��������
��γ������Ȱ����廮��Ϊ����Ⱥ���ٰ�ÿȺ�ֱ��ֶ�����Ϊ���ɴ�Ⱥ���ٰ�ÿ����Ⱥ������Ϊ��С��Ⱥ���������ƣ�ֱ�����嵥λ������ʱ����һ��������������س�ȡ����Ⱥ���ڶ�������ѡȺ�зֱ�����س�ȡ���ɴ�Ⱥ���������ƣ�ֱ����ȡ������λ�����磬ijʡͳ�ƾ�Ҫ�����ʡũ����������������ȫʡ100����������س�20���أ�������ѡ��ÿ�����ж�����3���磬������ѡ�ĸ����ж������10��ũ��������һ������Ϊn=10��3��20��600�����������������γ����������Ǵ�Ⱥ����Ⱥ���С��Ⱥ��ÿȺ�Ĵ�С������ȣ�Ҳ���Բ���ȣ�ÿ�δ���ѡȺ�г�ȡ��һ�ε�Ⱥ������λ����������ȣ�Ҳ���Բ���ȡ��������������γ���Ϊ�����������ص㼰�йؼ��㷽����
�����γ������ԣ��Ƚ����廮��ΪR��Ⱥ����ÿȺ�а���M��i(i=1��2����R)����λ�������嵥λ��N=M��1+M��2+����+M��R������ʱ����һ�δ�R��Ⱥ������س�ȡr��Ⱥ���ڶ��δ���ѡ��r��Ⱥ�зֱ�������س�m��i(i=1��2����r)����λ������һ������Ϊn=m��1+m��2+����m��r�����������γ��������ͳ�������Ⱥ�����Ľ�ϣ���������֯��ʽ�������Ȱ�����ֳ�����Ⱥ���ࡢ�飩����֮ͬ�����±���ʾ������7-8����
���ֳ�����֯��ʽ�ıȽ�
��7-8��
Ϊ�˼��㣬��ÿȺ�а����ĵ�λ������ȣ�ΪM�����Ӹ���ѡȺ�г���ĵ�λ��Ҳ����ȣ�Ϊm�������γ������ȴ�����R��Ⱥ������س�ȡr��Ⱥ���ִ�r��Ⱥ�ж��ֱ�����س�ȡm����λ�����һ������n=rm��������
��xij����ʾ��i��i=1��2����r��������Ⱥ�е�j��j=1��2����m������һ��λ�ı�־ֵ�����i������Ⱥ������ƽ����![]() Ϊ��
��
ȫ������ƽ����![]() ������ʽ���㣺
������ʽ���㣺
���γ����ij���ƽ���������ƽ������ƽ������������ɣ�һ����ƽ��Ⱥ�ڷ����![]() ���裺
���裺
ΪȺ�䷽������γ�����ƽ�����ij���ƽ������xΪ��
��ʵ�ʼ���ʱ��������ָ�꣨��Ⱥ�ڷ���![]() ��Ⱥ�䷽��
��Ⱥ�䷽��![]() �����õ�ʱ��������Ӧ������ָ����档
�����õ�ʱ��������Ӧ������ָ����档
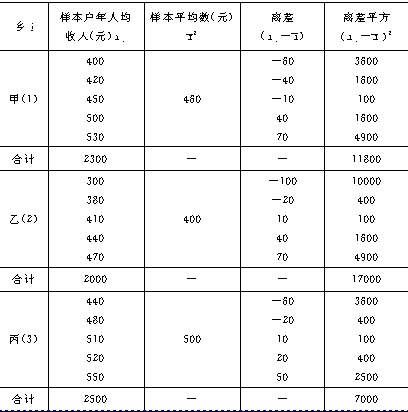
������8��ij��ͳ�ƾ���ȫ��15�����������ȡ3���磬��ÿ�����1500ũ��������ÿ����ѡ���������ȡ5��ũ������ȫ����������ĵ��飬���������������±�������6-9��
��7-9 ��������������� ��
����95���ĸ��ʹ���ȫ��ũ�����˾���������䡣
����������ʾ��
��Ⱥ�ڷ�����������ϼ��㣩��
��ƽ�����ڷ��
�֣�Ⱥ�䷽����������ϼ��㣩��
����ƽ�����̪�x�������ظ�����ʱΪ��
�ڲ��ظ�����ʱΪ��
����F(t)=95%ʱ�����ʶ�t=1.96��ȫ��ũ�����˾���������䣬�ظ�����ʱΪ��
������9����2010�꣩���ݵڶ��ξ����ղ�����ij����������ҵ���廧10����ҵ��Ա��30���ˡ�����Ըõ�������ҵ���廧�ľ�Ӫ�����չ�������顣Ϊ�Ƚϲ�ͬ���������������ԣ��ֱ���ü�����������Դ�ҵ��Ա��Ϊ�ֲ��־�ķֲ�������������ղ�С��ΪȺ��λ����Ⱥ����������ȡ500�����廧��500�����廧��60���ղ�С�����ں�500�����廧�����е��飬���������±���
|
�������� |
�õ�������ҵ���廧���۶� | |
|
�����ֵ����Ԫ�� |
�������ֵ����Ԫ2�� | |
|
��������� |
535 |
2982 |
|
�ֲ�������� |
542 |
765 |
|
��Ⱥ���� |
524 |
6535 |
Ҫ��
1���ֱ�������95%���ʱ�֤�̶������ֳ�������������ҵ���廧���۶�������������������ֳ��������µĹ�����������ߣ�������1λС����
2�����ЧӦ��Deff���ĸ�����ʲô�������ֲ������������Ⱥ���������ЧӦ��������3λС����
3����ʵ�ʳ��������������ֳ��������������Խ��м�Ҫ���ۡ�
����������ʾ����������=Z*S ���ʱ�֤�ȳ��Ա���
����� E=��/Y
1������������źֱ�Ϊ��54.6�� 27.7�� 80.8
�����������E=1.96*54.6/535=0.2
�ֲ����������E=1.96*27.7/542=0.3
��Ⱥ���� ��E=1.96*80.8/524=0.1
2�����ЧӦ������Ϊ���������ʽ�µij���������Լ����������ʽ�³���������̡���ͬ������ʽ�µ����ЧӦ�ֱ�Ϊ��
�����������deff=1 �ֲ����������deff<=1
��Ⱥ���������deff>= 1��е���������deff��1
�ֲ����=765/2982=0.257
��Ⱥ����=6535/2982=2.191
�����������ϵͳ�������ֲ�����Ĺ�ͬ�ص����ڳ���������ÿһ�����屻��ȡ�ĸ�����ȣ���������Щ���������Ŀ��Ժ�ƽ�ԣ����м�������������������ij����������ڽ���ϵͳ�����ͷֲ����ʱ��Ҫ�õ�����������������������еĸ���������ʱ�������ü�����������������еĸ������϶�ʱ��������ϵͳ����������֪�����ɲ������Եļ��������ʱ������һ������ǡ�����о��������������ʱ�������÷ֲ����.
������10����ij��ʵʩһ��������飬�����������飬Ԥ�ƿջ���Ϊ5%����ܷõ�ԭ����ɵ��ش���Ϊ15%����Ҫ��֤������Ч�������ܹ��ﵽ200��������Ӧ��ȡ������������
����������ʾ����Ҫ��ȡX������5%�Ŀջ��ʣ����ܳ��ϵ�ֻ�У�1-5%�����ش���Ϊ15%��˵���ܻش��ֻ��1-15%
X��1-5%����1-15%��=200 X=247.2 ȡ��=248
������11����2012�꣩��֪ij��ҵְ��������������£�
|
��ͬ���� ������ |
ְ������ ��Ni�� |
�������� (ni) |
��ƽ�����루Ԫ�� (x) |
������Ԫ�� ��Si�� |
|
������ |
200 |
10 |
13200 |
480 |
|
һ������ |
1600 |
80 |
8040 |
300 |
|
������ |
1200 |
60 |
6000 |
450 |
|
�ϼ� |
3000 |
150 |
- |
- |
�����ϱ����ϼ��㣺1��������ƽ�����룻2����ƽ������ij�����3������Ϊ95%ʱ��ְ����ƽ������Ŀ��ܷ�Χ��
����������ʾ��
1��������ƽ�������
![]()
ְ����ƽ������=![]() ��Ԫ��
��Ԫ��
2����ƽ������ij�����
![]()
�������![]()
����Ϊ95%ʱ��ְ����ƽ������Ŀ��ܷ�Χ:
�����������=0.6827��29.60=20.21��Ԫ����
����ֵ=630.67-20.21=610.46��Ԫ��
����ֵ=630.67+20.21=650.88��Ԫ��
ְ����ƽ������Ŀ��ܷ�Χ: ��610.46Ԫ--650.88Ԫ����
 |
|||||||||||||||||||||||||||||||||
| ��ͳ��ʦѡ������ | |||||||||||||||||||||||||||||||||
|
��ѵ�γ�
��ʦ����
�����ײ�
|
|||||||||||||||||||||||||||||||||





- �ͷ�����ʦ
