 |
12 | |||||
| �γ� | ��� | ���� | ���� |
��ͳ��ʵ�������������㾫��29
�����ڳ�������ԭ���ͷ�����
һ���������Ƶ��ص㪥
�������ƾ�������������Ļ����ϣ�������ָ�������ָ���������ƺ��жϡ����ڳ��������ǽ����ڸ����ۺ�����ͳ�ƻ����ϵģ�����б�Ҫ�Գ������Ƶ��ص���Է������Ա�Գ�������ԭ���ܹ���һ�������⡣��
1.�������ƴ����Ͽ���һ�ֹ����ƶϷ��������ݳ�������ĸ�����Ա��������������ǴӸ���һ�㡢�Ӳ��ֵ������һ����ʶ���̡����磬ij�ض�ũ�������г������飬��N�鲥����ʳ�ĸ����У�������n�鲥����ʳ�ĸ��أ���һ�������ʳƽ��Ķ�����ﵽ600��ڶ��������ʳƽ��Ķ����Ҳ�ﵽ��600������������Ľ������������n����ص���ʳƽ��Ķ����Ϊ600��ڴ˻����ϣ��������ƵĽ����ǣ�����ȫ��������ʳƽ��Ķ������600�����ң����������ƶ�����һ���İ��ճ̶ȵġ���Ȼ���ַ����Ǿ��嵽һ�㣨���������壩�Ĺ����ƶϷ�������һ�ֿ����Ե������������DZ�Ȼ�Ľ��ۡ�
2.�����������õ��Ǹ��ʹ��Ʒ�����������ѧ��������ʵ���ϳ��������Ǹ���С�����¼�ԭ�������ƶϵġ�С�����¼�ԭ����Ϊ���������Լ�С���¼����������Ϊ0.1����0.5����1���ȵ��¼���һ�ι۲�������в����ܷ�����Ȼ����ij�¼���һ�������۲��й�Ȼ�����ˣ���˵��������С�����¼������������ָ�����ƶ�����ָ����һ�ָ��ʹ��Ʒ��������DZ�Ȼ�Ľ��ۡ���
3.�������ƵĽ��۴��ڳ���������ص�����һ�����Ѿ��й����ܡ���������ڳ�����������������ġ����еġ������Կ��Ʋ������������2016���ͳ��ʦ���Խ̲�19.9Ԫ ��ͳ��ʦ���Ա�����338Ԫ����������ָ����346401794��QQͬ�ţ�����ͳ��ʦ�������⡢��١�����ʱ�䡢��ѵ����ͳ��ʦʵ��̡̳����Ե����顢������⡢��ͳ��ʦ�������� ��
��
�����������Ƶ���������
����ȷ��������ָ�꣬�������Բ��ò�ͬ�ļ��㷽���������õ�����ָ�꣬����������ͬ������������Ҫ�Ƚϸ��ֹ����������ӡ�һ�������Ĺ�������Ӧ����������������������
1.��ƫ�ԡ���ָÿһ�ε�����ָ����δ֪����ָ����ܲ�ͬ��Ҳ��ƫ���ƫС��Ȼ��һ���õĹ�������ƽ���Ͽ�Ӧ�õ��������Ƶ�����ָ�ꡣ���仰˵������ָ�����ֵӦΧ��������ָ����Χ��������ϵͳ��ƫ�������
![]()
2.һ���ԡ���ָ������ָ���������ָ��Ҫ������������ִ�ʱ������ָ������������ָ�ꡣ�������������ţ��У���
![]()
3.��Ч�ԡ���ָ������ָ���������ָ��Ҫ����Ϊ�����������ķ�Ӧ�ñ������������ķ���С����
�����������Ʒ�����
���������ֳƲ������ơ���������ָ���������ƶ�����ָ�ꡣ�������Ƶķ��������֣�һ�ǵ���ƣ�����������ơ��ַ������£���
1.����ơ�Ҳ�ƶ�ֵ���ƣ����ǰ�����ָ��ֱ����Ϊδ֪������ָ��Ĺ���ֵ�����磬ij���������ѡ��100����������������40��ӵ�б��䡣������������������ӵ�б���Ļ�������Ϊ40����������õ���Ƶķ��������Եó��Ľ����Ǹó��е�����ָ��ȫ������ӵ�б���Ļ�������Ϊ40������
2.������ơ�����һ���ĸ��ʱ�֤�̶�Ҫ���£����������Ĺ۲�ֵ����������ָ����һ���ķ�Χ�ڱ仯����
������2��ij��������ũ�����������飬�����ظ������������ѡ��100ĶС����أ����ƽ��Ķ����Ϊ500�����Ϊ80���֪����������С����ص�ǧ��֮һ�����ɿ��̶�Ϊ99.73��ʱ���Թ��Ƹõ���С��ƽ��Ķ�����ı仯��Χ����
����������ʾ��
![]()
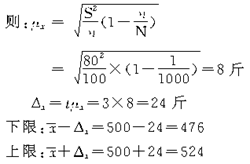
���Ըõ���С��ƽ��Ķ�����ı仯��ΧΪ476�524���
������3��ij���а����ظ����������ѡ��100����������������70��ӵ�вʵ磬��֪����������ȫ������ǧ��֮һ�����ɿ��̶�Ϊ95.45��ʱ���Թ��Ƴ��о���ӵ�вʵ�Ļ�����ռ�ı��ط�Χ��
������������ʾ��
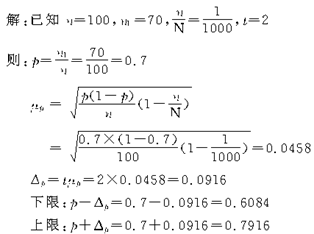
���Ըó��о���ӵ�вʵ�Ļ�����ռ���صķ�ΧΪ60.84����79.16������
���������ӿ��Կ���������ƵIJ���Ϊ����
���ȣ�Ҫȷ������Ҫ��ָ�꣬������ָ���������������
��Σ������������䣺��
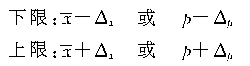
������4��ij��У�����ظ����������ѡ�ٷ�֮һ�Ĵ�ѧ�����г������飬������ǵ������������£���
��7-3��
Ҫ������94.45���ĸ��ʱ�֤���ơ���
��1����Уȫ����ѧ����ƽ�����ߵķ�Χ����
��2����Уȫ����ѧ��������170�������ϵ�������Χ����
����������ʾ����Ŀ�е�����Ҫ��һ��������ƽ���������⣬��һ���������������⡣��
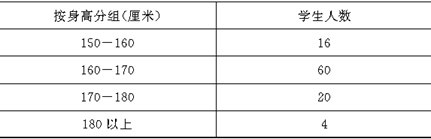
��7-4��
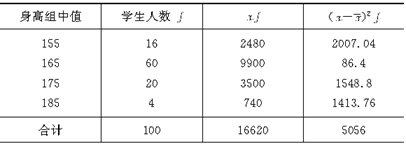
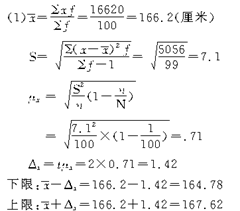

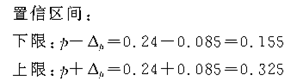
������Χ���������䣺��
���ޣ�10000��0.155��1550�˪�
���ޣ�10000��0.325��3250�˪�
���Ը�Уȫ����ѧ��������170�������ϵ�������ΧΪ1550-3250�ˡ���
��ͳ��ʵ�������������㾫��29
�����ڳ�������ԭ���ͷ�����
һ���������Ƶ��ص㪥
�������ƾ�������������Ļ����ϣ�������ָ�������ָ���������ƺ��жϡ����ڳ��������ǽ����ڸ����ۺ�����ͳ�ƻ����ϵģ�����б�Ҫ�Գ������Ƶ��ص���Է������Ա�Գ�������ԭ���ܹ���һ�������⡣��
1.�������ƴ����Ͽ���һ�ֹ����ƶϷ��������ݳ�������ĸ�����Ա��������������ǴӸ���һ�㡢�Ӳ��ֵ������һ����ʶ���̡����磬ij�ض�ũ�������г������飬��N�鲥����ʳ�ĸ����У�������n�鲥����ʳ�ĸ��أ���һ�������ʳƽ��Ķ�����ﵽ600��ڶ��������ʳƽ��Ķ����Ҳ�ﵽ��600������������Ľ������������n����ص���ʳƽ��Ķ����Ϊ600��ڴ˻����ϣ��������ƵĽ����ǣ�����ȫ��������ʳƽ��Ķ������600�����ң����������ƶ�����һ���İ��ճ̶ȵġ���Ȼ���ַ����Ǿ��嵽һ�㣨���������壩�Ĺ����ƶϷ�������һ�ֿ����Ե������������DZ�Ȼ�Ľ��ۡ�
2.�����������õ��Ǹ��ʹ��Ʒ�����������ѧ��������ʵ���ϳ��������Ǹ���С�����¼�ԭ�������ƶϵġ�С�����¼�ԭ����Ϊ���������Լ�С���¼����������Ϊ0.1����0.5����1���ȵ��¼���һ�ι۲�������в����ܷ�����Ȼ����ij�¼���һ�������۲��й�Ȼ�����ˣ���˵��������С�����¼������������ָ�����ƶ�����ָ����һ�ָ��ʹ��Ʒ��������DZ�Ȼ�Ľ��ۡ���
3.�������ƵĽ��۴��ڳ���������ص�����һ�����Ѿ��й����ܡ���������ڳ�����������������ġ����еġ������Կ��Ʋ������������2016���ͳ��ʦ���Խ̲�19.9Ԫ ��ͳ��ʦ���Ա�����338Ԫ����������ָ����346401794��QQͬ�ţ�����ͳ��ʦ�������⡢��١�����ʱ�䡢��ѵ����ͳ��ʦʵ��̡̳����Ե����顢������⡢��ͳ��ʦ�������� ��
�����������Ƶ���������
����ȷ��������ָ�꣬�������Բ��ò�ͬ�ļ��㷽���������õ�����ָ�꣬����������ͬ������������Ҫ�Ƚϸ��ֹ����������ӡ�һ�������Ĺ�������Ӧ����������������������
1.��ƫ�ԡ���ָÿһ�ε�����ָ����δ֪����ָ����ܲ�ͬ��Ҳ��ƫ���ƫС��Ȼ��һ���õĹ�������ƽ���Ͽ�Ӧ�õ��������Ƶ�����ָ�ꡣ���仰˵������ָ�����ֵӦΧ��������ָ����Χ��������ϵͳ��ƫ�������
![]()
2.һ���ԡ���ָ������ָ���������ָ��Ҫ������������ִ�ʱ������ָ������������ָ�ꡣ�������������ţ��У���
![]()
3.��Ч�ԡ���ָ������ָ���������ָ��Ҫ����Ϊ�����������ķ�Ӧ�ñ������������ķ���С����
�����������Ʒ�����
���������ֳƲ������ơ���������ָ���������ƶ�����ָ�ꡣ�������Ƶķ��������֣�һ�ǵ���ƣ�����������ơ��ַ������£���
1.����ơ�Ҳ�ƶ�ֵ���ƣ����ǰ�����ָ��ֱ����Ϊδ֪������ָ��Ĺ���ֵ�����磬ij���������ѡ��100����������������40��ӵ�б��䡣������������������ӵ�б���Ļ�������Ϊ40����������õ���Ƶķ��������Եó��Ľ����Ǹó��е�����ָ��ȫ������ӵ�б���Ļ�������Ϊ40������
2.������ơ�����һ���ĸ��ʱ�֤�̶�Ҫ���£����������Ĺ۲�ֵ����������ָ����һ���ķ�Χ�ڱ仯����
������2��ij��������ũ�����������飬�����ظ������������ѡ��100ĶС����أ����ƽ��Ķ����Ϊ500�����Ϊ80���֪����������С����ص�ǧ��֮һ�����ɿ��̶�Ϊ99.73��ʱ���Թ��Ƹõ���С��ƽ��Ķ�����ı仯��Χ����
����������ʾ��
![]()
���Ըõ���С��ƽ��Ķ�����ı仯��ΧΪ476�524���
������3��ij���а����ظ����������ѡ��100����������������70��ӵ�вʵ磬��֪����������ȫ������ǧ��֮һ�����ɿ��̶�Ϊ95.45��ʱ���Թ��Ƴ��о���ӵ�вʵ�Ļ�����ռ�ı��ط�Χ��
������������ʾ��
���Ըó��о���ӵ�вʵ�Ļ�����ռ���صķ�ΧΪ60.84����79.16������
���������ӿ��Կ���������ƵIJ���Ϊ����
���ȣ�Ҫȷ������Ҫ��ָ�꣬������ָ���������������
��Σ������������䣺��
������4��ij��У�����ظ����������ѡ�ٷ�֮һ�Ĵ�ѧ�����г������飬������ǵ������������£���
��7-3��
Ҫ������94.45���ĸ��ʱ�֤���ơ���
��1����Уȫ����ѧ����ƽ�����ߵķ�Χ����
��2����Уȫ����ѧ��������170�������ϵ�������Χ����
����������ʾ����Ŀ�е�����Ҫ��һ��������ƽ���������⣬��һ���������������⡣��
��7-4��
������Χ���������䣺��
���ޣ�10000��0.155��1550�˪�
���ޣ�10000��0.325��3250�˪�
���Ը�Уȫ����ѧ��������170�������ϵ�������ΧΪ1550-3250�ˡ���
 |
|||||||||||||||||||||||||||||||||
| ��ͳ��ʦѡ������ | |||||||||||||||||||||||||||||||||
|
��ѵ�γ�
��ʦ����
�����ײ�
|
|||||||||||||||||||||||||||||||||





- �ͷ�����ʦ
