 |
12 | |||||
| �γ� | ��� | ���� | ���� |
��ͳ��ʵ�������������㾫��28
�ڶ��ڳ�������ļ����������
һ�������������
1.���壬Ҳ��Ϊȫ�����塣��ָ��Ҫ��ʶ���о������ȫ�壬�ɾ���ij�ֹ�ͬ���ʵ����λ����ɡ����磬�о�ȫ�������ͥ������ˮƽ����ȫ���ľ����������塣�о�һ����Ʒ���������ʱ����ȫ����Ʒ���������塣�˴�����ĸ������һ�½��ܵĸ�����һ�µġ���
2.������Ҳ��Ϊ�������壬������������Ǵ������������ȡ����������������Dz��ֵ�λ�ļ����塣���˵��������һ�������壬�����˵��������һ��С���塣С�����Ǵ������һ���֣���С������������嵥λ�����磬ȫ�����˿������壬ʡ�˿ڡ����˿ڡ����˿ھ�ΪС���壬���ܰ�С������Ϊ�����嵥λ����
����һ�����⣬������Ψһȷ���ģ�������������Ψһ�ġ�һ��������ܳ�ȡ��������������˵�������ɾ��й�ͬ���ʵ����λ�����ɵļ��ϣ�Ҳ�ɳ�Ϊĸ������ĸ�壩�������������Ը�ĸ����һ���Ӽ������������壬��˿����������������������ƶ��������������������2016���ͳ��ʦ���Խ̲�19.9Ԫ ��ͳ��ʦ���Ա�����338Ԫ����������ָ����346401794��QQͬ�ţ�����ͳ��ʦ�������⡢��١�����ʱ�䡢��ѵ����ͳ��ʦʵ��̡̳����Ե����顢������⡢��ͳ��ʦ��������
��������ָ�������ָ�ꪥ
1.����ָ�꣬Ҳ��Ϊĸ���������Ʋ���������ָ���Ǹ������������λ�ı�־ֵ����ģ���ӳ���������������һ���������������������ָ�ꡣ���磬ȫ�����˿ڵ����������˿�����ƽ�����䡢�����ʵ���������ָ�ꡣ��Щ����ָ�꣬�Ӳ�ͬ�ĽǶȣ���ӳ������ֲ��Ļ���״������Ҫ����������˵�������ƽ����������ı����DZ�ʾ����ֲ��ļ������ƺ��������Ƶ���������ָ�ꡣ���磬ij��������С���ƽ��Ķ����Ϊ500�����Ϊ30�����С���ƽ��Ķ����Ϊ450�����Ϊ32�����ָ�귴ӳ�˼��ص�С��ƽ��Ķ������ˮƽ������������ƽ��Ķ������ˮƽ������ˮƽ�Ƚϼ��С����ȡ���
����������Ψһȷ���ģ���������ָ��Ҳ����Ψһ�ԡ����磬ȫ�����Ĵ��˿��ղ��������ȫ�����˿ڡ�����ָ���˿�����11.3���ˡ����ָ����Ψһ�ģ������ܳ���������ͬ���˿����֡���
2.����ָ�꣬Ҳ��Ϊͳ�������Ƿ�ӳ���������������ġ�������ֵ���������IJ�ͬ���仯������ָ����һ�����������һ���棬����ָ�귴ӳ�������ķֲ�״����������������һ���棬����ָ��������ָ��Ĺ�����������֮��������ҵ��������ֲ���״�����������������磬�������ض�С��IJ������г������飬��ÿ�γ�ȡ50Ķ����һ�γ�������С��ƽ��Ķ����Ϊ490��ڶ��γ�������С��ƽ��Ķ����Ϊ505������γ�������С��ƽ��Ķ����Ϊ495�������˽��ж�Σ�ÿ�ε�����ָ����ֵ�����в�ͬ�����˴�ʮ�ֽӽ�������һ�㶼��ƽ��Ķ����500�����Ҳ�������
����һ��������Գ�ȡ�����������������ͬ��һ��˵������ָ����ֵҲ��ͬ���������ָ����ֵ����Ψһȷ���ġ���
���õ�����ָ�������ָ�����£�
��7-1����
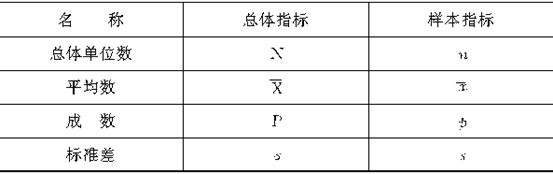 �����Ҫ˵������������λ��������Ŀ��������ͬ�ĸ��������λ����Ҳ����������Ҳ��������������һ���������������ĵ�λ����������Ŀ��ָ�������п��ܳ�ȡ�������ĸ��������磬���Ǵ�һ����8����ɵ�������ÿ�γ����2�˹��ɵ���������������λ��n=2��������Ŀ������˳����ظ��������������ܲ�����������Ŀ��64����
�����Ҫ˵������������λ��������Ŀ��������ͬ�ĸ��������λ����Ҳ����������Ҳ��������������һ���������������ĵ�λ����������Ŀ��ָ�������п��ܳ�ȡ�������ĸ��������磬���Ǵ�һ����8����ɵ�������ÿ�γ����2�˹��ɵ���������������λ��n=2��������Ŀ������˳����ظ��������������ܲ�����������Ŀ��64����
�����ظ������Ͳ��ظ�������
���ݳ��������IJ�ͬ�����ظ������Ͳ��ظ��������֡���
�ظ������Ǵ�����N����λ�������ȡһ������Ϊn��������ÿ�γ��һ����λ��ѡ��һ����λʱ����ǰһ���ѳ��еĵ�λ�Ż����������²μӳ�ѡ�����һ����λ���ظ����еĿ��ܣ�Ҳ�ƷŻس����������ظ��������ǽ��ѳ��еĵ�λ���ٷŻ����壬���ÿ����λ���ֻ�ܳ���һ�Σ�Ҳ�в��Żس�������
���ݶ�������Ҫ��ͬ���п���˳������Ͳ�����˳��������֡���
����˳����ָ���ȳ��е�λA���ٳ���B��������ΪAB�����ȳ��е�λB������е�λA��������ΪBA����Ӧ�ü���Ϊ������ͬ������������������˳����ɰ�AB��BA����ͬһ����������
�ѳ����������IJ�ͬ���Ƿ���˳�����������������������
1.����˳����ظ�������Ŀ�������ظ�����������������Ŀ�����Ŀ�����й�ʽ���㣺��
![]()
2.����˳��IJ��ظ�������Ŀ�������ظ�����������������Ŀ�����Ŀ�����й�ʽ���㣺��
![]()
3.������˳����ظ�������Ŀ�������ظ����������������Ŀ�����Ŀ�����й�ʽ���㣺��
![]()
4.������˳��IJ��ظ�������Ŀ�������ظ����������������Ŀ�����Ŀ�����й�ʽ���㣺��
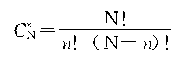
�ġ�����ƽ�����ͳ���������
1.��������ָ�������������������һ�ִ��������������ԭ�����ʱ���ڲ����ǵǼ�����ϵͳ�����������£��������ڲ�ͬ����������ó���ͬ�Ĺ�����������������
��Ҫע��������ͳ��������е����������������𡣳��������п��ܲ����Ǽ���Ҳ���ܲ���ϵͳ��ƫ����Щ�����dz������Ǽ�����ϵͳ��ƫ������˼�����á��������⣬���Է�ֹ����⡣�����������������ģ��dz������������еġ���
2.����ƽ��������ƽ�����������ƽ�����ı������ӳ������ƽ����������ƽ������ƽ�����̶ȡ���
�����Ԧ̪�x��ʾ����ƽ�����ij���ƽ�����̪�p��ʾ���������ij���ƽ����M��ʾȫ�����ܵ�������Ŀ����
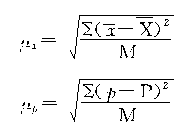
������ʽ�����˳���ƽ�����Ĺ�ϵ��������������ƽ����������������Ȳ���֪��������Ҳ������ȫ������������ָ��ֵ������������ʽ���������ƽ�����ʵ�����Ƿdz����ѵġ�������ܵĹ�ʽ���Dz�ȡ��ѧ�ķ����Ƶ������ģ�����Ȥ��ͬ־���Բ����йص�����ͳ�������еij������۲��֡���
��һ������ƽ�����ij���ƽ����
���ظ������������£���
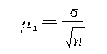
�ڲ��ظ������������£���
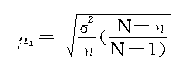
�ڲ��ظ�����ƽ����ʽ�����Ա�ʾΪ���½��ƹ�ʽ����
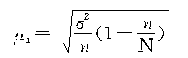
���������������ij���ƽ����
���ظ������������£���
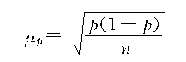
�ڲ��ظ������������£���
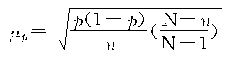
���ظ�����ƽ����ʽ�����Ա�ʾΪ���½��ƹ�ʽ����
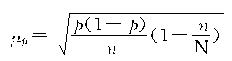
���������ѿ������ظ������벻�ظ������ij���ƽ����ʽ���ڶ��θ�ʽ�����һ����������![]() �����������������С��1����˲��ظ�����ƽ���������С���ظ�����ƽ������
�����������������С��1����˲��ظ�����ƽ���������С���ظ�����ƽ������
Ӱ�����ƽ��������Ҫ�����������ĸ�����
��1������ң������ƽ�����Ĵ�С�����ȣ��������屻�о��ı�־ֵ֮��IJ���̶�Խ��ʱ������ƽ������Խ��֮��Ȼ����
��2����������n�������ƽ�����Ĵ�С�ɷ��ȣ�������ȡ��������λ��Խ��ʱ������ƽ������ԽС������ȡ��������λ������ʱ������ƽ�������Ӧ���Щ����
��3�����������IJ�ͬ���Գ���ƽ������Ӱ���Dz��ò��ظ������ij���ƽ�����ҪС�ڲ����ظ������ij���ƽ������
��4����������֯��ʽ��ͬ�Գ���ƽ�����Ҳ�н�������Ӱ�죬��������������Ľڽ��ܡ���
������ʽ�ļ���������õ��������ң�����һ������£����Ȳ��������ⷽ������ϣ���ʱҲ��������������S���������
��������ļ��㹫ʽ���£���
��һ����ʽ��
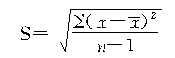
��������Ȩʽ��
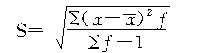
����һ��������ƽ�����ļ��㹫ʽ������ʽ����
����ƽ�����ij���ƽ������
�ظ�������
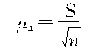
���ظ�������
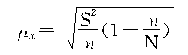
3.�����������������������ָ����ָ�������ָ��֮��������Ŀ��ܷ�Χ����������ָ����Ψһȷ���ģ�������ָ����������ָ�긽�����²���������֮����ܲ�������Ҳ���ܷ������������Ծ���ֵ��ʽ��ʾ������ָ�������ָ��֮�����������������½��ޣ������µľ���ֵ����ʽ��ʾ����

��������ƽ�������������һ����δ֪�ģ���Ҫ������ƽ�����������������й��ơ����Գ�����������ʵ��������ϣ������ƽ����X[TX-]��������ƽ����x[TX-*3]����x�ķ�Χ�ڣ��������P������������p����P�ķ�Χ�ڣ������������ֵ����ʽ���Ա�ʾΪ����
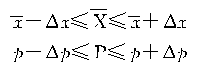
���������ϵ�Ҫ�����������ͨ���ı���ʽ���£���
�����������=���ʶȡ�����ƽ����
![]()
������1��ij���в��ò��ظ����������ѡ��100����������������60��ӵ�вʵ磬��֪����������ȫ�о���ǧ��֮һ�������ʶ�Ϊ2ʱ���Լ������ƽ�����ͳ���������
����������ʾ����
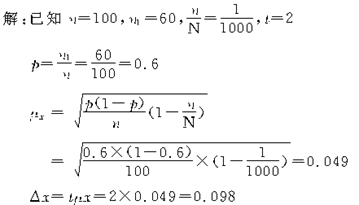
�����t���Ӧ�Ŀɿ��̶�ΪF(t)�����ǵĹ�ϵ���£�������ֵ����
��7-2��
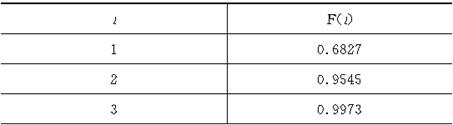
����һ����ֵ�ɲ������ĸ�¼����̬�ֲ����ʱ�����
��ͳ��ʵ�������������㾫��28
�ڶ��ڳ�������ļ����������
һ�������������
1.���壬Ҳ��Ϊȫ�����塣��ָ��Ҫ��ʶ���о������ȫ�壬�ɾ���ij�ֹ�ͬ���ʵ����λ����ɡ����磬�о�ȫ�������ͥ������ˮƽ����ȫ���ľ����������塣�о�һ����Ʒ���������ʱ����ȫ����Ʒ���������塣�˴�����ĸ������һ�½��ܵĸ�����һ�µġ���
2.������Ҳ��Ϊ�������壬������������Ǵ������������ȡ����������������Dz��ֵ�λ�ļ����塣���˵��������һ�������壬�����˵��������һ��С���塣С�����Ǵ������һ���֣���С������������嵥λ�����磬ȫ�����˿������壬ʡ�˿ڡ����˿ڡ����˿ھ�ΪС���壬���ܰ�С������Ϊ�����嵥λ����
����һ�����⣬������Ψһȷ���ģ�������������Ψһ�ġ�һ��������ܳ�ȡ��������������˵�������ɾ��й�ͬ���ʵ����λ�����ɵļ��ϣ�Ҳ�ɳ�Ϊĸ������ĸ�壩�������������Ը�ĸ����һ���Ӽ������������壬��˿����������������������ƶ��������������������2016���ͳ��ʦ���Խ̲�19.9Ԫ ��ͳ��ʦ���Ա�����338Ԫ����������ָ����346401794��QQͬ�ţ�����ͳ��ʦ�������⡢��١�����ʱ�䡢��ѵ����ͳ��ʦʵ��̡̳����Ե����顢������⡢��ͳ��ʦ��������
��������ָ�������ָ�ꪥ
1.����ָ�꣬Ҳ��Ϊĸ���������Ʋ���������ָ���Ǹ������������λ�ı�־ֵ����ģ���ӳ���������������һ���������������������ָ�ꡣ���磬ȫ�����˿ڵ����������˿�����ƽ�����䡢�����ʵ���������ָ�ꡣ��Щ����ָ�꣬�Ӳ�ͬ�ĽǶȣ���ӳ������ֲ��Ļ���״������Ҫ����������˵�������ƽ����������ı����DZ�ʾ����ֲ��ļ������ƺ��������Ƶ���������ָ�ꡣ���磬ij��������С���ƽ��Ķ����Ϊ500�����Ϊ30�����С���ƽ��Ķ����Ϊ450�����Ϊ32�����ָ�귴ӳ�˼��ص�С��ƽ��Ķ������ˮƽ������������ƽ��Ķ������ˮƽ������ˮƽ�Ƚϼ��С����ȡ���
����������Ψһȷ���ģ���������ָ��Ҳ����Ψһ�ԡ����磬ȫ�����Ĵ��˿��ղ��������ȫ�����˿ڡ�����ָ���˿�����11.3���ˡ����ָ����Ψһ�ģ������ܳ���������ͬ���˿����֡���
2.����ָ�꣬Ҳ��Ϊͳ�������Ƿ�ӳ���������������ġ�������ֵ���������IJ�ͬ���仯������ָ����һ�����������һ���棬����ָ�귴ӳ�������ķֲ�״����������������һ���棬����ָ��������ָ��Ĺ�����������֮��������ҵ��������ֲ���״�����������������磬�������ض�С��IJ������г������飬��ÿ�γ�ȡ50Ķ����һ�γ�������С��ƽ��Ķ����Ϊ490��ڶ��γ�������С��ƽ��Ķ����Ϊ505������γ�������С��ƽ��Ķ����Ϊ495�������˽��ж�Σ�ÿ�ε�����ָ����ֵ�����в�ͬ�����˴�ʮ�ֽӽ�������һ�㶼��ƽ��Ķ����500�����Ҳ�������
����һ��������Գ�ȡ�����������������ͬ��һ��˵������ָ����ֵҲ��ͬ���������ָ����ֵ����Ψһȷ���ġ���
���õ�����ָ�������ָ�����£�
��7-1����
�����Ҫ˵������������λ��������Ŀ��������ͬ�ĸ��������λ����Ҳ����������Ҳ��������������һ���������������ĵ�λ����������Ŀ��ָ�������п��ܳ�ȡ�������ĸ��������磬���Ǵ�һ����8����ɵ�������ÿ�γ����2�˹��ɵ���������������λ��n=2��������Ŀ������˳����ظ��������������ܲ�����������Ŀ��64����
�����ظ������Ͳ��ظ�������
���ݳ��������IJ�ͬ�����ظ������Ͳ��ظ��������֡���
�ظ������Ǵ�����N����λ�������ȡһ������Ϊn��������ÿ�γ��һ����λ��ѡ��һ����λʱ����ǰһ���ѳ��еĵ�λ�Ż����������²μӳ�ѡ�����һ����λ���ظ����еĿ��ܣ�Ҳ�ƷŻس����������ظ��������ǽ��ѳ��еĵ�λ���ٷŻ����壬���ÿ����λ���ֻ�ܳ���һ�Σ�Ҳ�в��Żس�������
���ݶ�������Ҫ��ͬ���п���˳������Ͳ�����˳��������֡���
����˳����ָ���ȳ��е�λA���ٳ���B��������ΪAB�����ȳ��е�λB������е�λA��������ΪBA����Ӧ�ü���Ϊ������ͬ������������������˳����ɰ�AB��BA����ͬһ����������
�ѳ����������IJ�ͬ���Ƿ���˳�����������������������
1.����˳����ظ�������Ŀ�������ظ�����������������Ŀ�����Ŀ�����й�ʽ���㣺��
![]()
2.����˳��IJ��ظ�������Ŀ�������ظ�����������������Ŀ�����Ŀ�����й�ʽ���㣺��
![]()
3.������˳����ظ�������Ŀ�������ظ����������������Ŀ�����Ŀ�����й�ʽ���㣺��
![]()
4.������˳��IJ��ظ�������Ŀ�������ظ����������������Ŀ�����Ŀ�����й�ʽ���㣺��
�ġ�����ƽ�����ͳ���������
1.��������ָ�������������������һ�ִ��������������ԭ�����ʱ���ڲ����ǵǼ�����ϵͳ�����������£��������ڲ�ͬ����������ó���ͬ�Ĺ�����������������
��Ҫע��������ͳ��������е����������������𡣳��������п��ܲ����Ǽ���Ҳ���ܲ���ϵͳ��ƫ����Щ�����dz������Ǽ�����ϵͳ��ƫ������˼�����á��������⣬���Է�ֹ����⡣�����������������ģ��dz������������еġ���
2.����ƽ��������ƽ�����������ƽ�����ı������ӳ������ƽ����������ƽ������ƽ�����̶ȡ���
�����Ԧ̪�x��ʾ����ƽ�����ij���ƽ�����̪�p��ʾ���������ij���ƽ����M��ʾȫ�����ܵ�������Ŀ����
������ʽ�����˳���ƽ�����Ĺ�ϵ��������������ƽ����������������Ȳ���֪��������Ҳ������ȫ������������ָ��ֵ������������ʽ���������ƽ�����ʵ�����Ƿdz����ѵġ�������ܵĹ�ʽ���Dz�ȡ��ѧ�ķ����Ƶ������ģ�����Ȥ��ͬ־���Բ����йص�����ͳ�������еij������۲��֡���
��һ������ƽ�����ij���ƽ����
���ظ������������£���
�ڲ��ظ������������£���
�ڲ��ظ�����ƽ����ʽ�����Ա�ʾΪ���½��ƹ�ʽ����
���������������ij���ƽ����
���ظ������������£���
�ڲ��ظ������������£���
���ظ�����ƽ����ʽ�����Ա�ʾΪ���½��ƹ�ʽ����
���������ѿ������ظ������벻�ظ������ij���ƽ����ʽ���ڶ��θ�ʽ�����һ����������![]() �����������������С��1����˲��ظ�����ƽ���������С���ظ�����ƽ������
�����������������С��1����˲��ظ�����ƽ���������С���ظ�����ƽ������
Ӱ�����ƽ��������Ҫ�����������ĸ�����
��1������ң������ƽ�����Ĵ�С�����ȣ��������屻�о��ı�־ֵ֮��IJ���̶�Խ��ʱ������ƽ������Խ��֮��Ȼ����
��2����������n�������ƽ�����Ĵ�С�ɷ��ȣ�������ȡ��������λ��Խ��ʱ������ƽ������ԽС������ȡ��������λ������ʱ������ƽ�������Ӧ���Щ����
��3�����������IJ�ͬ���Գ���ƽ������Ӱ���Dz��ò��ظ������ij���ƽ�����ҪС�ڲ����ظ������ij���ƽ������
��4����������֯��ʽ��ͬ�Գ���ƽ�����Ҳ�н�������Ӱ�죬��������������Ľڽ��ܡ���
������ʽ�ļ���������õ��������ң�����һ������£����Ȳ��������ⷽ������ϣ���ʱҲ��������������S���������
��������ļ��㹫ʽ���£���
��һ����ʽ��
��������Ȩʽ��
����һ��������ƽ�����ļ��㹫ʽ������ʽ����
����ƽ�����ij���ƽ������
�ظ�������
���ظ�������
3.�����������������������ָ����ָ�������ָ��֮��������Ŀ��ܷ�Χ����������ָ����Ψһȷ���ģ�������ָ����������ָ�긽�����²���������֮����ܲ�������Ҳ���ܷ������������Ծ���ֵ��ʽ��ʾ������ָ�������ָ��֮�����������������½��ޣ������µľ���ֵ����ʽ��ʾ����
��������ƽ�������������һ����δ֪�ģ���Ҫ������ƽ�����������������й��ơ����Գ�����������ʵ��������ϣ������ƽ����X[TX-]��������ƽ����x[TX-*3]����x�ķ�Χ�ڣ��������P������������p����P�ķ�Χ�ڣ������������ֵ����ʽ���Ա�ʾΪ����
���������ϵ�Ҫ�����������ͨ���ı���ʽ���£���
�����������=���ʶȡ�����ƽ����
![]()
������1��ij���в��ò��ظ����������ѡ��100����������������60��ӵ�вʵ磬��֪����������ȫ�о���ǧ��֮һ�������ʶ�Ϊ2ʱ���Լ������ƽ�����ͳ���������
����������ʾ����
�����t���Ӧ�Ŀɿ��̶�ΪF(t)�����ǵĹ�ϵ���£�������ֵ����
��7-2��
����һ����ֵ�ɲ������ĸ�¼����̬�ֲ����ʱ�����
 |
|||||||||||||||||||||||||||||||||
| ��ͳ��ʦѡ������ | |||||||||||||||||||||||||||||||||
|
��ѵ�γ�
��ʦ����
�����ײ�
|
|||||||||||||||||||||||||||||||||





- �ͷ�����ʦ
